참고: 가상 면접 사례로 배우는 대규모 시스템 설계 기초, 알렉스 쉬
단일 서버
웹 앱, 데이터베이스, 캐시 등 모든 요소들이 단 한 대의 서버에서 실행되는 형태이다.

단일 서버의 사용자 요청 흐름
- 사용자 단말 ➡️ DNS : 사용자가 도메인(ex, www.naver.com)을 DNS에 질의
- DNS ➡️ 사용자 단말 : DNS에서 도메인을 IP 주소(ex, 223.130.200.236)로 변환해 응답
- 사용자 단말 ➡️ 서버 : 사용자 단말에서 IP 주소를 통해 서버로 필요한 데이터 요청(ex, HTTP 요청)
- 서버 ➡️ 사용자 단말 : 서버에서 요청한 데이터를 사용자 단말에 전송
데이터베이스 추가(웹 서버+DB서버)
사용자 수가 증가하게 되면, 위 단일 서버에 데이터베이스 서버를 추가할 수 있다.

데이터데이스 추가 시, 사용자 요청 흐름
- 사용자 단말 ➡️ DNS : 사용자가 도메인(ex, www.naver.com)을 DNS에 질의
- DNS ➡️ 사용자 단말 : DNS에서 도메인을 IP 주소(ex, 223.130.200.236)로 변환해 응답
- 사용자 단말 ➡️ 서버 : 사용자 단말에서 IP 주소를 통해 서버로 필요한 데이터 요청(ex, HTTP 요청)
- 서버 ➡️ 데이터베이스 : 사용자가 요청한 데이터를 데이터베이스에 쿼리 요청
- 데이터베이스 ➡️ 서버 : 쿼리에 맞는 데이터를 찾아 서버에 응답
- 서버 ➡️ 사용자 단말 : 서버에서 요청한 데이터를 사용자 단말에 전송
데이터베이스 선택의 기준
관계형 데이터베이스: 열과 칼럼으로 데이터를 구분할 수 있고, 관계에 따라 Join해 합칠 수 있다.(ex, MySQL, 오라클, PostgreSQL)
비-관계형 데이터베이스: Join 연산이 없으며, 키-값 저장소(key-value store), 그래프 저장소(graph store), 칼럼 저장소(column store), 문서 저장소(document sotre)로 나뉜다.
대부분의 경우, 관계형 데이터베이스(RDBMS)를 선택하며, 아래의 기준에 따라 비-관계형 데이터베이스(NoSQL)를 선택할 수 있다.
- 아주 낮은 응답 지연시간이 요구되는가? (Low Latency)
- 관계형 데이터가 아닌, 비정형 데이터인가?
- 데이터를 직렬화 혹은 역직렬화 할 수 있기만 하면 되는가?
- 아주 많은 양의 데이터를 저장해야하는가?
직렬화/역직렬화: 데이터를 저장, 전송, 공유할 때 필요한 과정.
직렬화(Serialization): 객체 혹은 데이터 구조를 저장/전송 가능한 형태(ex, JSON, XML, 바이트 배열)로 변환하는 과정. (ex, 자바의 객체를 DB에 저장가능한 형태로 변환)
역직렬화(Deserialization): DB의 데이터를 원래의 형태로 복원하는 과정 (ex, DB에서 읽어온 데이터를 자바 객체로 변환)
수직적 규모 확장 VS 수평적 규모 확장
수직적 규모 확장, 스케일 업(Scale up)
서버에 CPU, RAM 등 고사양의 자원을 추가하는 것. 일반적으로 트래픽 양이 적을 때는 스케일 업 방법이 적합하다.
장점
- 비교적 단순하다.
단점
- 한계가 있다.(CPU, RAM 같은 자원을 무한히 확장할 수 없으므로)
- 자동복구, 다중화 방안이 없다. ➡️ 장애 발생시, 완전히 중단 (서버 개수는 고정이므로, 고정된 양의 서버들이 중단되면, 서비스도 중단된다.)
수평적 규모 확장, 스케일 아웃(Scale out)
서버의 개수를 더 많이 추가해 성능을 향상시키는 것. 트래픽 양이 높을 때, 대규모 시스템 설계 시 적합하다. 로드밸런서( 부하 분산기)를 통해 구축한다.
장점
- 한계가 없다. (서버는 무한히 늘릴 수 있으므로)
- 자동 복구 및 다중화 가능. (장애 발생 시, 다른 서버를 통해 서비스 제공 가능)
단점
- 비교적 복잡하다
로드밸런서(Load Balancer, 부하 분산기)
로드밸런서: 부하 분산 집합(Load Balancing Set)에 속한 웹 서버들에게 트래픽을 고르게 분산시켜주는 장치.
- 로드밸런서의 Public IP로 접속.
- 로드밸런서가 Private IP로 부하 분산 집합 내 서버들에게 요청을 전송.
자동 복구: 아래 그림에서 server A가 중단되면, 트래픽을 server B로 전송. 서비스가 완전히 중단되는 경우를 방지 가능.
다중화 가능: 트래픽이 빠르게 증가할 경우, 웹 서버를 추가하면 됨.

데이터베이스 다중화
대부분의 데이터베이스는 다중화를 지원한다. 보통 주(master)-부(slave) 관계로 나뉘며, 주 데이터베이스에 원본을 저장하고 부 데이터베이스에 사본을 저장한다.
- Witre Operation(쓰기 연산)은 주 데이터베이스로 전달
- Read Opertation(읽기 연산)은 부 데이터베이스에 전달
- 통상적으로 Read Operation이 더 많으므로, 부 데이터베이스가 주 데이터베이스보다 많다.
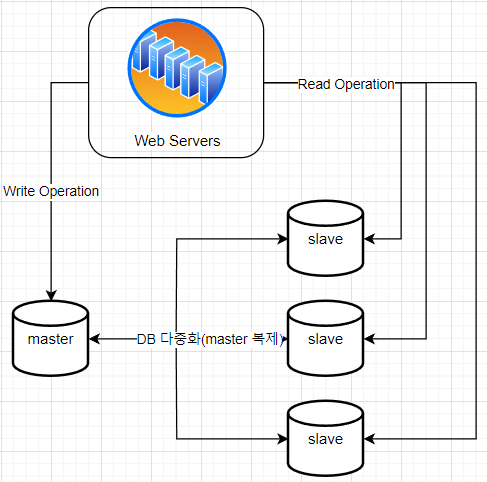
주 데이터베이스(mater database)
- Write Operation(INSERT, UPDATE, DELETE).
- 변경 사항을 하위 부 데이터베이스로 복사해서 데이터의 일관성을 유지
- 부 데이터베이스보다 적다.
부 데이터베이스(slave database)
- Read Operation
- 주 데이터베이스보다 많다.
Master, Slave 별 다운 시나리오
Master Server가 다운될 경우
- Master가 다운될 경우, 여러 Slave 중 하나가 새로운 Master가 된다. Slave가 Master로 변함에 따라 개수가 적어지므로, 추가적인 Slave를 증설한다.
- Master에서 Slave로의 데이터 동기화가 일어나기 전 Master가 다운된다면, 데이터의 누락이 있을 수 있다. 이런 경우, 복구 스크립트를 실행해 추가해야 한다. (조금 더 복잡하지만 좋은 방법으론 다중 마스터, 원형 다중화 방식이 있다.)
Slave Server가 다운될 경우
- Slave Server가 한 대 일 경우, 모든 연산은 한시적으로 모두 Master에 전달되고, 즉시, 새로운 Slave 서버를 추가해 대체한다.
- Slave가 여러 대 일 경우, 장애 서버를 제외한 Slave들이 연산을 처리한다.
데이터베이스 다중화 시 장점
장점
- 병렬화에 대한 성능 이점 : master-slave 다중화 모델에서 모든 Write Operation은 Master에서 처리하고, Read Operation은 여러 Slave에서 분산 처리한다. 따라서 master-slave간 1차 병렬, 여러 slave 간 2차 병렬 연산으로 성능의 이점이 있다.
- 안정성 증가 : 여러 DB를 물리적으로 떨어뜨려 놓으면, 일부 DB가 파괴되어도, 데이터가 보존된다.
- 가용성 : master 데이터베이스를 복제한 여러 Slave 데이터베이스가 있으므로, 하나의 DB 서버에 장애가 발생해도 계속 서비스할 수 있다.
위의 모든 것들을 합한 모습은 아래와 같다.
